必备
- 三台CentOS7服务器:
- 192.168.253.130
- 192.168.253.131
- 192.168.253.132
- 主机名修改对应为:
- CentOS7-130 (主)
- CentOS7-131
- CentOS7-132
安装(在130(主))
分别修改主机名
eg.192.168.253.130将主机名修改为130
hostnamectl set-hostname CentOS7-130
修改hosts文件
vim /etc/hosts
192.168.253.130 CentOS7-130
192.168.253.131 CentOS7-131
192.168.253.132 CentOS7-132
重启一下吧,重新加载
reboot
设置ssh免密登录
安装Hadoop
下载并上传至CentOS7的/usr/local/
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
解压
tar -zxvf hadoop-3.3.5.tar.gz
vim /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop-3.3.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
source /etc/profile
修改配置文件
hadoop-env.sh
cd /usr/local/hadoop-3.3.5/etc/hadoop
vim hadoop-env.sh
配置你本机的JAVA_HOME,可通过 echo $JAVA_HOME 查询
export JAVA_HOME=/usr/local/jdk
root用户需多添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS7-130:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.5/dfs/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>CentOS7-130:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS7-132:9868</value>
</property>
</configuration>
yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS7-131</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim /usr/local/hadoop-3.3.5/etc/hadoop/workers
CentOS7-130
CentOS7-131
CentOS7-132
迁移(131、132)
安装rsync
yum install rsync -y
自定义xsync
cd /usr/local/bin/
vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in CentOS7-130 CentOS7-131 CentOS7-132
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
chmod +x xsync
迁移
xsync xsync
xsync /usr/local/hadoop-3.3.5/
xsync /etc/profile
启动
集群架构图
| CentOS7-130 | CentOS7-131 | CentOS7-132 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourcesManager、NodeManager | NodeManager |
130(主)
如果是集群第一次启动,需要再主节点(130)格式化NameNode,此时为130
hdfs namenode -format
启动HDFS
cd /usr/local/hadoop-3.3.5/
sbin/start-dfs.sh
jps
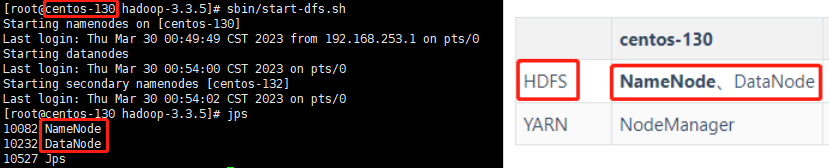
页面访问

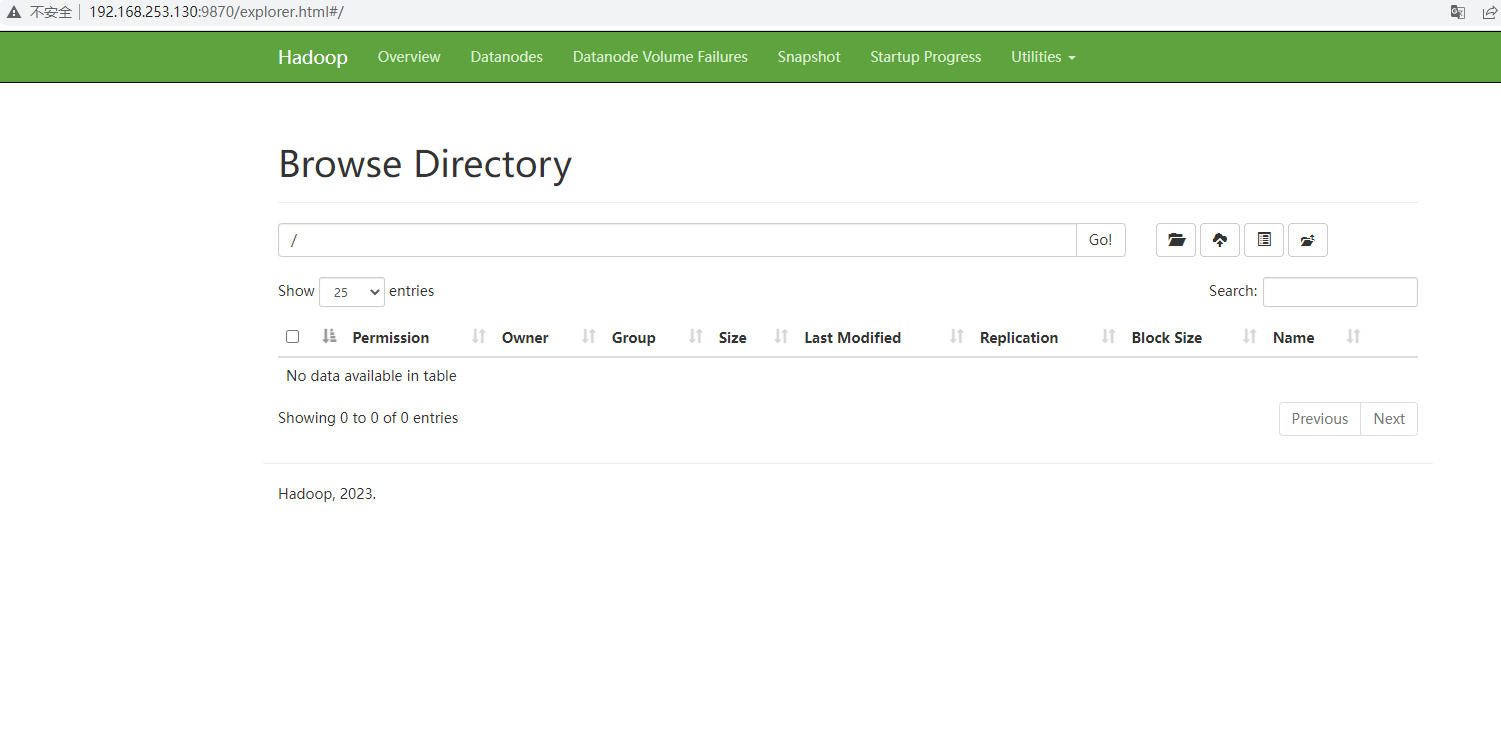
此时,HDFS的部署成功
131的启动情况:
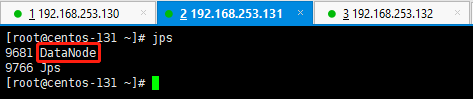
132的启动情况:

131(配置了ResourceManager的节点)
cd /usr/local/hadoop-3.3.5/
sbin/start-yarn.sh
输入网址